Ramp发布SWE-Bench私有基准:Claude Fable 5以87.5%胜率夺冠
Ramp发布SWE-Bench私有基准:Claude Fable 5以87.5%胜率夺冠
金融科技独角兽 Ramp 发布了针对前沿 AI 编码智能体的私有测试基准 Ramp SWE-Bench。Ramp SWE-Bench 包含 80 个源自 Ramp 真实生产环境的后端开发任务,旨在解决公共评估数据集因模型预训练而导致的数据泄露与指标饱和问题。
测试任务均提取自 Ramp 内部 AI 编码助手 Inspect 成功部署到生产环境的真实拉取请求(PR)。每个任务重构了 PR 提交前的基础代码库,保留合并的代码与测试作为黄金标准,并提取工程师在 Inspect 对话中的原始意图作为提示词。评估采用 mini-swe-agent 沙箱环境,以单次运行成功通过所有测试且不破坏现有功能(pass@1)作为通过标准。
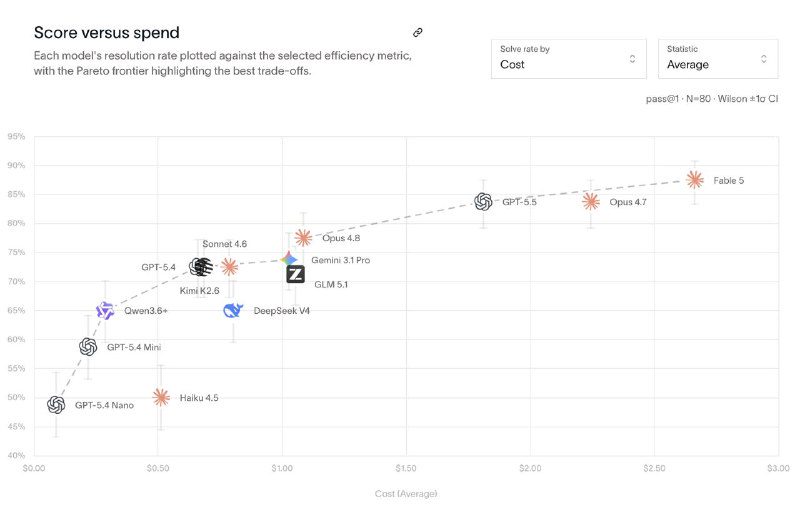
根据公布的 14 款模型横向评测结果,Anthropic 最新推出的 Claude Fable 5 以 87.5% 的解决率高居榜首。Claude Opus 4.7 和 GPT-5.5 并列第二,解决率均为 83.75%。Claude Opus 4.8 虽然解决率为 77.5%,但单次任务平均运行时间缩短至 8 分 30 秒,单次运行成本仅为 1.09 美元,不足 Fable 5 运行成本的 40%,展现出极佳的成本效益。
测试数据还揭示了不同模型在价格与性能间的权衡。国产模型 Kimi K2.6 与 GLM 5.1 解决率相近,分别为 72.5% 与 71.25%,但 Kimi K2.6 的平均成本为 0.69 美元,比 GLM 5.1 便宜约 34%。在轻量级模型中,GPT-5.4 Mini 以 58.75% 的解决率领先 Claude Haiku 4.5 约 10 个百分点,且平均成本和步骤数均减半。Ramp 指出,随着模型走向应用,性能、速度与成本的权衡正成为工程落地时的关键考量。
信源:https://labs.ramp.com/swebench#explore