阿里发布智能体基准PawBench:优秀框架可助小模型「下克上」
t.meGeneral06/05 11:1615 阅读
阿里发布智能体基准PawBench:优秀框架可助小模型「下克上」
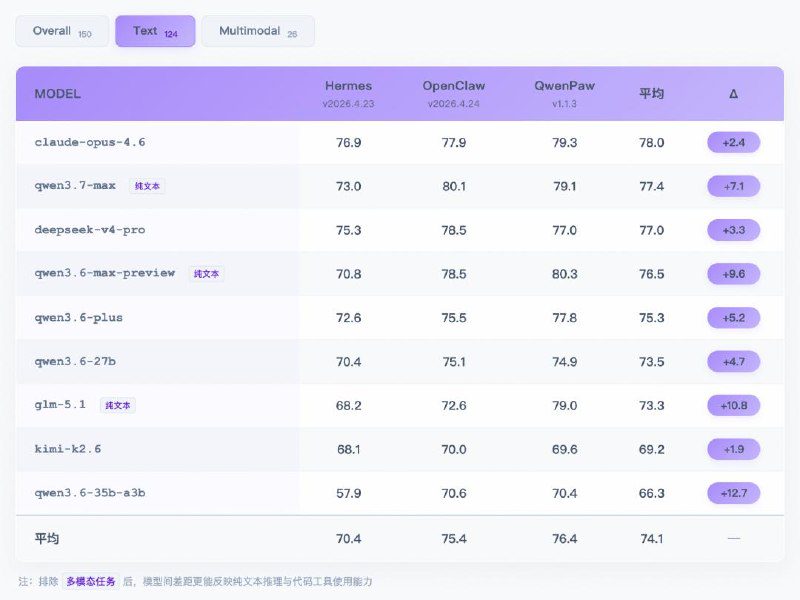
阿里通义实验室推出智能体评测基准 PawBench v1.0,首次将底座模型与运行框架纳入统一评测体系。评测针对 9 个大模型与 Hermes、OpenClaw、QwenPaw 三款框架进行交叉测试,包含 150 道真实任务与 4050 个测试单元。
结果表明,运行框架的设计直接决定了智能体能力是否能稳定落地。在模型相同的情况下,三款框架存在明显的性能极差,QwenPaw 得分 76.4,OpenClaw 得分 75.4,而 Hermes 仅为 70.4。6.4 分的差距堪比一次重大的模型版本升级。优秀的设计甚至能让小模型实现「下克上」:在 Hermes 框架中 GLM 5.1 仅得 68.2 分,而在 QwenPaw 框架下较小规模的 Qwen3.6-35b-a3b 却拿到了 70.4 分。
通过分析运行轨迹,框架表现差异源于对工作区产物缺乏实质校验、工具路径约束宽松以及工具表过大增加了模型决策负担。多数框架在本地专属技能(Skill)的主动发现以及网页搜索的零配置可用性上也存在明显短板。评测团队提出了框架设计的四项基本原则:充分告知(Inform Fully)、按需装备(Equip on Demand)、主动监控(Monitor Actively)和弹性恢复(Recover Gracefully),建议开发者通过完善工程治理来释放底座模型的实际能力。
信源:https://mp.weixin.qq.com/s/Q1fa3KwT63HBOF2fmWKzlg
原文链接纠错/举报